


处理不平衡数据的7个技巧
大多数机器学习算法对于不平衡数据集的处理不是很好。 以下七种技术可以帮你训练分类器来检测异常类。
1.使用正确的评估指标
对使用不平衡数据生成的模型应用不恰当的评估指标可能是危险的。

想象一下,我们的训练数据如上图所示。 如果使用精度来衡量模型的好坏,使用将所有测试样本分类为“0”的模型具有很好的准确性(99.8%),但显然这种模型不会为我们提供任何有价值的信息。
在这种情况下,可以应用其他替代评估指标,例如:
精度/特异性:有多少个选定的相关实例。
调用/灵敏度:选择了多少个相关实例。
F1得分:精度和召回的谐波平均值。
MCC:观察和预测的二进制分类之间的相关系数。
AUC:正确率与误报率之间的关系。
2.重新采样训练集
除了使用不同的评估标准外,还可以选择不同的数据集。使平衡数据集不平衡的两种方法:欠采样和过采样。
欠采样通过减少冗余类的大小来平衡数据集。当数据量足够时使用此方法。通过将所有样本保存在少数类中,并在多数类中随机选择相等数量的样本,可以检索平衡的新数据集以进一步建模。
相反,当数据量不足时会使用过采样,尝试通过增加稀有样本的数量来平衡数据集。不是去除样本的多样性,而是通过使用诸如重复,自举或SMOTE等方法生成新样本(合成少数过采样技术)
请注意,一种重采样方法与另一种相比没有绝对的优势。这两种方法的应用取决于它适用的用例和数据集本身。过度取样和欠采样不足结合使用也会有很好的效果。
3.以正确的方式使用K-fold交叉验证
值得注意的是,使用过采样方法来解决不平衡问题时,应适当地应用交叉验证。切记,过采样会观察到稀有的样本,并根据分布函数自举生成新的随机数据。如果在过采样之后应用交叉验证,那么我们所做的就是将模型过度适应于特定的人工引导结果。这就是为什么在过采样数据之前应该始终进行交叉验证,就像实现特征选择一样。只有对数据进行重复采样,可以将随机性引入到数据集中,以确保不会出现过拟合问题。
4.组合不同的重采样数据集
生成通用模型的最简单方法是使用更多的数据。问题是,开箱即用的分类器,如逻辑回归或机森随林,倾向于通过丢弃稀有样例来推广。一个简单的最佳实现是建立n个模型,使用少数类的所有样本和数量充足类别的n个不同样本。假如您想要组合10个模型,需要少数类1000例,随机抽取10.000例多数类的样本。然后,只需将10000个样本分成10个块,训练出10个不同的模型。

如果您有大量数据,那么这种方法很简单,完美地实现水平扩展,因此您可以在不同的集群节点上训练和运行模型。集合模型也趋于一般化,使得该方法容易处理。
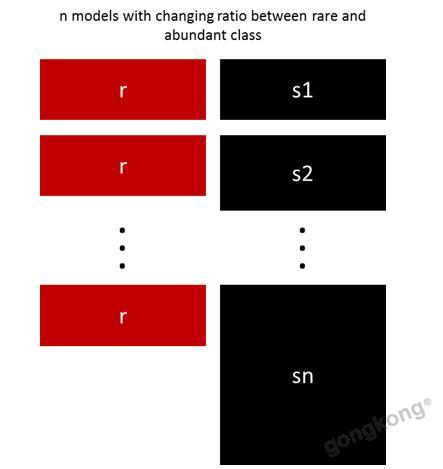
5.用不同比例重新采样
以前的方法可以通过少数类和多数类之间的比例进行微调。最好的比例在很大程度上取决于所使用的数据和模型。但是,不是在整体中以相同的比例训练所有模型,合并不同的比例值得尝试。 所以如果训练了10个模型,对一个模型比例为1:1(少数:多数),另一个1:3甚至是2:1的模型是有意义的。 根据使用的模型可以影响一个类获得的权重。
6. 对多数类进行聚类
Sergey Quora提出了一种优雅的方法[2]。他建议不要依赖随机样本来覆盖训练样本的种类,而是将r个分组中的多数类进行聚类,其中r为r中的样本数。对于每个组,只保留质心(样本的中心)。然后该模型仅保留了少数类和样本质心来训练。
7.设计自己的模型
以前的所有方法都集中在数据上,并将模型作为固定的组件。但事实上,如果模型适用于不平衡数据,则不需要对数据进行重新采样。如果数据样本没有太多的倾斜,著名的XGBoost已经是一个很好的起点,因为该模型内部对数据进行了很好的处理,它训练的数据并不是不平衡的。但是再次,如果数据被重新采样,它只是悄悄进行。
通过设计一个损失函数来惩罚少数类的错误分类,而不是多数类,可以设计出许多自然泛化为支持少数类的模型。例如,调整SVM以相同的比例惩罚未被充分代表的少数类的分类错误。




 投诉建议
投诉建议
提交

新大陆自动识别精彩亮相2024华南国际工业博览会

派拓网络被Forrester评为XDR领域领导者

智能工控,存储强基 | 海康威视带来精彩主题演讲

展会|Lubeworks路博流体供料系统精彩亮相AMTS展会

中国联通首个量子通信产品“量子密信”亮相!