


怎样做供应链的需求预测?
需求预测是所有供应链规划的基础,供应链中的所有推动流程(push process)都是根据对顾客需求的预测来进行的,然而,所有拉动流程(pull process)都是根据对市场需求的响应来进行的。对于推动流程,供应链管理者必须对生产、运输或任何其他需要计划的活动的预期水平进行计划,对于拉动流程,供应链管理者必须计划的是可获得的产能和库存的水平,而不是实际实施的数量。但是,不管是推动式供应链还是拉动式供应链,供应链管理者必须做的首要工作都是对未来顾客的需求进行预测。
企业和供应链管理者应当了解预测具有如下特点:
1.预测总是不精确的,所以我们必须兼顾预测结果和预测误差。
2.长期预测的精度往往比短期预测低,也就是说,长期预测的标准差相对于均值而言比短期预测要大些。
3.综合预测往往比分解预测更精确,因为相对于均值来说,综合预测的标准差较小。
4.一般来说,企业越靠近供应链的上游(或者离消费者越远),其接收到的信息失真就越大,这方面的一个经典例子就是牛鞭效应,或称啤酒效应。
人们往往认为需求预测是一种艺术,认为一切皆为偶然。但是实际上,企业对顾客过去购买行为的把握将有助于对顾客未来购买行为的预测。所以,为了预测顾客需求,企业首先需要识别那些影响未来需求的因素,并确定这些因素与未来需求之间的关系。在预测过程中,企业必须平衡客观因素和主观因素这两个方面,必须了解以下与需求预测相关的各种因素:过去的需求;产品补货提前期;广告计划或其他营销活动的力度;经济状况;价格促销计划;竞争企业采取的行动。
预测方法可分为以下四大类:
一是定性预测法,主要依赖人们的主观判断。
二是时间序列预测法,运用历史需求数据对未来需求进行预测。
三是因果关系预测法,通过预测有关联性的外界因素的变化来预测未来需求。
四是仿真法,通过模拟消费者的选择来预测需求。
实际上,研究表明多种预测方法结合使用得到的综合预测值将比单独使用任何一种预测方法更为有效。
当未来需求与历史需求、增长模式和季节性变化相关时,最适合使用时间序列法。无论采用哪一种预测方法,都存在一些不能用过去的需求模式解释的随机因素,因此,任何观察到的需求都可以分解成系统成分和随机成分:观察的需求(O)=系统成分(S)+随机成分(R)。系统成分是指需求的期望值,它由下面几方面组成:需求水平是剔除季节性因素影响后的当前需求;需求趋势是需求在下一期增长或衰退的比率;季节系数为可预测的需求季节性波动。随机成分就是在预测中偏离系统需求的那一部分。预测的目的就在于剔除随机成分,并对系统成分进行估计,一般来说,一种好的预测方法的预测误差大小大致等同于需求中的随机成分。
以下五项基本步骤对有效进行预测有很大帮助:
1.理解预测的目标。所有预测都支持以预测为基础的决策,所以重要的第一步就是明确识别这些决策。
2.整合整个供应链的需求计划和预测。企业应当将预测与整个供应链中的所有计划活动联系起来,如产能计划、促销计划。
3.识别影响需求预测的主要因素。企业必须识别影响需求预测的一些需求、供给和产品相关的其他因素。
4.以合适的综合水平进行预测。既然综合预测比分解预测更为精确,那么在进行预测时选择合适的综合预测水平就变得非常重要。
5.建立预测绩效和误差衡量标准。企业必须确定明确的绩效衡量标准以评价预测的准确性和时效性,这些衡量标准应该与企业在预测基础上制定的商业决策目标密切相关。
任何预测方法的目标都是对需求的系统成分进行预测,并对随机成分进行估计。就其最一般的形式,需求数据的系统成分包含需求水平、需求趋势和季节系数,计算系统成分的等式可以采用如下所示的各种模型。乘法型:系统成分=需求水平*需求趋势*季节系数;加法型:系统成分=需求水平+需求趋势+季节系数;混合型:系统成分=(需求水平+需求趋势)*季节系数。某一特定预测的系统成分的具体表示形式,取决于需求的特性。对于每种形式,企业都可以采用静态预测和适应性预测两种方法。
一种是静态预测法。静态预测法假定待评估的系数成分中的需求水平、需求趋势和季节系数都不随观测到的新需求而改变,在这种情况下,我们利用历史数据来对这些参数进行估计,然后应用于所有未来预测中。另一种是适应性预测法。在适应性预测法中,需求水平、需求趋势和季节系数都要根据每次观测到的实际需求值进行修改。适应性预测法的优点在于预测时所有被观测到的新数据都被考虑其中了。
一种好的预测方法应当抓住需求的系统成分而不是随机成分,随机成分是通过预测误差的形式表现出来。预测误差包含了有价值的信息,基于下面两个原因管理者必须对预测误差进行仔细分析:1.管理者通过误差分析来判定现行的预测方法是否准确预测了需求的系统成分。2.所有应变计划都必须考虑预测误差。只要预测到的误差值在历史误差估计范围内,企业就可以继续使用现行的预测方法。如果某次误差值远大于历史误差估计范围,就说明现行的预测方法不再使用了或者需求发生了根本变化。如果所有的预测值都倾向于连续高于或低于实际需求,那么可能也是暗示预测方法需要改变了。当运用指数平滑法进行预测时,平滑指数的取值直接影响预测值对近期实际需求数据的敏感性。如果管理者想要很好地把握未来潜在的需求模式,则选用的平滑指数最好不要超过0.2。
鉴于预测中涉及大量的数据、预测次数的频繁性和尽可能获取高质量预测结果的重要性,信息技术(IT)自然在预测中发挥着重要作用。供应链IT系统中的预测模块通常被称作需求计划模块,是关键的供应链软件产品,在预测中发挥IT的功能是非常有益的。商业性的需求计划模块中包含多种相当先进或专有的预测算法,用这些方法求得的预测值通常比普通软件求得的预测值更精确。好的预测软件包可以为各式各样的产品提供预测,并结合最新的需求信息对预测值进行实时更新。这有助于企业快速响应市场的变化,避免延迟反应带来的成本。当然,没有一种工具是完美无缺的,在运用预测值和享受预测所带来的价值的同时,要记住这些分析工具无法对未来需求中一些更为定性的方面进行估计,而这可能只能凭预测者自己的经验和能力进行判断。
在未来计划中必须考虑预测误差带来的风险,预测误差可能导致库存、设备、运输、采购、定价甚至信息管理中严重的资源分配不当。很多因素都可能引起预测不精确,但其中少数因素会经常发生,值得关注。较长的提前期迫使企业提前更多时间作出预测,从而影响预测的可靠性。有两种降低预测风险的策略:提高供应链的响应性和利用需求集中的机会。提高响应性可以使企业降低预测误差,从而减少相关风险。加快响应速度和增加集中往往会增加成本,响应性的加快需要加大产能投资,而增加集中也会相应增加运输费用。为了实现风险缓解与成本之间的平衡,我们需要制定合适的风险缓解策略。比如对于日用商品,通过现货市场采购很容易弥补缺货,因此投入大量资金提高市场响应性是不值得的。只有当潜在的预测误差很大且商品价值远高于运输成本时,投资于集中才会是非常有益的。
在预测实践中,一要进行合作预测。与你的供应链合作者一起预测通常可获得更加精确的预测,虽然与合作者分享信息、建立合作预测关系需要花费时间和成本,但合作给供应链带来的利益通常远远大于初期成本。二要共享真正有价值的数据。数据是否有用要看我们处于供应链的什么位置,分享真正需要的数据可以减少IT投资,增加成功合作的可能性。三要区分实际需求和销售数据。为了获得真实的需求数据,需要根据产品的脱销信息、竞争者行为、价格以及促销行为等来对销售数据进行调整。如果做不到这一点,预测就不能反映当前的真实情况。




 投诉建议
投诉建议
提交

2025中欧绿色建筑工业化论坛9月北京启幕 全球智慧共推建筑产业“双碳”转型

喜讯!华强电子网荣获“2025年中国产业互联网创新企业”

深入实施“人工智能+”行动 浪潮软件集团看好人工智能+工业质检广阔前景,持续布局线缆行业智能质检
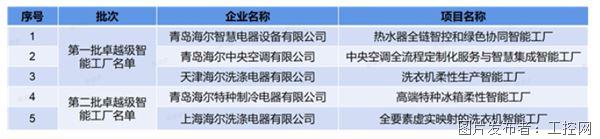
海尔新增2家卓越级智能工厂,总数品类行业双第一

深度剖析格力打破磁悬浮压缩机国外垄断,底气来自对自主创新的坚守!